Evolution of the Real-time Data Warehouses of the Alibaba Search and Recommendation Data Platform
Step up the digitalization of your business with Alibaba Cloud 2020 Double 11 Big Sale! Get new user coupons and explore over 16 free trials, 30+ bestselling products, and 6+ solutions for all your needs!
By Hologres, with Zhang Zhaoliang (Shiheng), Senior Technical Expert of the Alibaba Search Division
Background
The real-time data warehouses of the Alibaba Search and Recommendation Data Warehouse Platform support multiple e-commerce businesses, such as Taobao (Alibaba Group), Taobao Special Edition (Taobao C2M), and Eleme. Real-time data warehouses also support data applications, such as real-time dashboards, real-time reports, real-time algorithm training, and real-time A/B test dashboards.
Value of Data

We believe that data is the brainpower of the Alibaba Search and Recommendation System. This power is reflected in many areas, such as algorithm iteration, product operations, and decision-making. Therefore, it is important to understand how data flows in search and recommendation business scenarios. First, information is collected. When you use the search and recommendation feature of Taobao Mobile, tracking information on the server is triggered. Second, the collected information is processed by using offline and real-time extract, transform, load (ETL), and then loaded into the product engine. Third, we build an analysis system based on the engine to facilitate analysis and decision-making for algorithms and products. Fourth, after each decision is made, new content is produced and you see the business forms generated by the algorithm model. This results in a new round of data collection, processing, loading, and analysis. In this way, data is used to form a complete business process, in which each phase is very important.
Typical Search and Recommendation Scenarios
Real-time data is used in a variety of e-commerce search and recommendation scenarios, such as real-time analysis, algorithm application, and refined operations by the target audience.
1) Real-time Analysis and Algorithm Application
In real-time analysis and algorithm application scenarios, we use real-time data warehouses to build analysis reports, real-time dashboards, training algorithm models, and create other types of data products. Real-time data has the following characteristics in search and recommendation scenarios:
- Large data volumes: data storage in the petabytes every day
- Total entries in a single table: over 100 billion
- High queries per second (QPS): peak write speed of over 65 million records per second (RPS)
- Peak QPS: more than 200
- High data flexibility, diversified analysis scenarios, high-frequency analysis with specified conditions, and multi-dimensional queries without specified conditions
2) Refined Operations by Target Audience
In e-commerce operations, different operation strategies are always required for different target audiences. Traditionally, activities are delivered to users based on offline data. However, you will obtain the operation performance results on the next day. The real-time delivery to users and profiling are essential to efficiently observe and improve operational performance.
Real-time data warehouses provide real-time user behavior data, such as real-time unique visitors (UVs) and real-time turnover of users in different regions and of different ages, in the form of real-time dashboards and real-time reports. You also need to associate and compare the real-time data and offline data to provide real-time month-on-month and year-on-year data.
Typical Demands for Real-time Data Warehouses
The following typical demands for real-time data warehouses have been summarized during the construction stage:
- Grouping: For example, the GROUP BY clause is used in SQL statements to display industry metrics.
- Multi-dimensional Filtering: The array field is used to filter attribute values in scenario filtering, user filtering, product filtering, and merchant filtering.
- Aggregation: Real-time computing metrics such as SUM and COUNT_DISTINCT are aggregated based on details.
- A/B Test: The real-time gap between the test bucket and the benchmark bucket is calculated by parsing the bucket fields in log tracking.
- Specified Keys: To troubleshoot problems or check core merchant metrics, you need to specify the merchant ID or product ID to query real-time metrics, and aggregate data based on the ID field in the real-time details table.
- Unified Batch and Stream Processing: Real-time data warehouses only retain data generated in the last two days. Therefore, if you need to compare data on a year-on-year or month-on-month basis, you need to read offline data and real-time data for associative computing. This allows product or operation personnel to intuitively view the real-time data and contrast data in the upper-layer reports.
Real-time Data Warehouse Architecture
Based on these typical demands, we have abstracted the typical real-time data warehouse architecture, as shown in the following figure.
The business logs collected in real-time are cleansed and filtered by Realtime Compute for Apache Flink and then written into an online analytical processing (OLAP) engine. The OLAP engine needs to support multi-dimensional interactive queries, key-value (KV) queries, and unified stream and batch queries, to meet various business demands. The OLAP engine also needs to connect to various upper-layer business applications to provide online services.
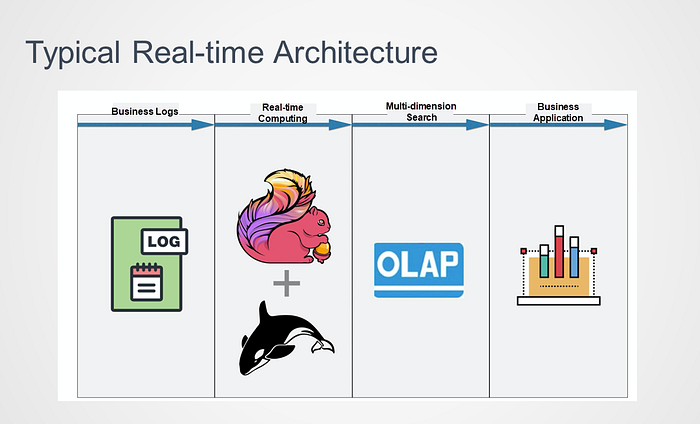
The following section describes the real-time architecture evolution in search and recommendation scenarios.
1.0 Real-time Data Warehouse Architecture
The 1.0 real-time data warehouse architecture consists of three phases, as shown in the following figure.

Data Collection
At the data collection layer, the upstream data collected in real-time is divided into user behavior logs, product dimension tables, merchant dimension tables, and user dimension tables. Dimension tables are used because the different businesses do not store all their information in logs during tracking. If all the information is stored in user behavior logs, the business is inflexible. Therefore, dimension tables are used to store more information for businesses.
The collected user behavior logs are written into Realtime Compute for Apache Flink. Data in dimension tables, such as user dimension tables and product dimension tables, is archived to MaxCompute. After preliminary calculations, the data synchronization tool (DataX) is used to synchronize the data to a batch processing engine.
Data Processing
During stream processing, Apache Flink preliminarily processes real-time user behavior logs at the data processing layer, including parsing, cleansing, and filtering data, and associating dimension tables.
During batch processing, to query and filter data by attributes in data queries and services, you must execute Apache Flink jobs to associate and compute real-time user behavior log data and data in dimension tables. This requires the batch processing system to support high QPS (up to 65 million QPS for a single table in the search service). Therefore, HBase is selected as the batch processing engine for dimension tables.
In an Apache Flink job, a real-time wide table with multiple dimension columns is output based on the user ID, product ID, and merchant ID in associated HBase dimension tables. Then, the data is output to the OLAP engine. To simplify real-time Apache Flink jobs and reduce the real-time computing workload, we filter real-time logs, associate them, and then output the detail data downstream. This requires the downstream engine to support KV queries, OLAP multidimensional interactive queries, and unified stream and batch queries.
Data Queries and Services
In the 1.0 architecture, we used the Lightning engine to carry the real-time detail data output by Apache Flink, implement unified stream and batch queries based on Lightning, and then provide unified real-time data query services for upstream applications.
However, Lightning has the following limits: It uses non-SQL queries, which is not user-friendly and requires secondary encapsulation for written SQL statements. Lightning uses public clusters without resource isolation. When you query a large amount of data, performance fluctuation and resource queuing are prone to occur, making queries time-consuming.
2.0 Real-time Data Warehouse Architecture
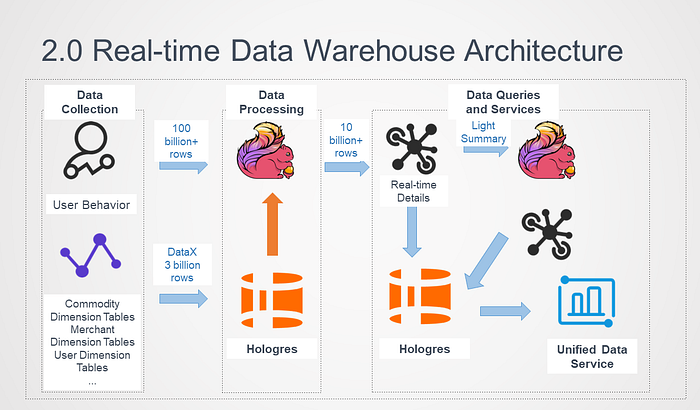
Due to the limits of Lightning, we wanted to find a more powerful alternative product that supported OLAP interactive queries and high-QPS dimension table validation and queries. Therefore, Hologres is used in the 2.0 real-time data warehouse architecture.
In the beginning, we replaced Lightning with Hologres to provide the KV and OLAP query capabilities, which eliminated the limits of Lightning. This architecture seems to work well. However, as the data volume increases, it takes longer to import data to HBase because data is also stored in dimension tables. This wastes a lot of resources. As the real-time requirements for online services increase, the disadvantages of HBase become more obvious.
One of the core capabilities of Hologres is to accelerate queries of offline data. Specifically, Hologres significantly accelerates the query of MaxCompute data by connecting to MaxCompute’s underlying resources. Therefore, we tried to replace HBase with Hologres for unified storage. In this way, data does not need to be imported and exported, and data is only stored in one copy.
In the data processing phase, data in user dimension tables, product dimension tables, and merchant dimension tables is stored in Hologres in row store mode to replace HBase storage. Apache Flink jobs directly read dimension tables in Hologres and associate them with behavior logs.
In the data query and service phase, all the real-time detailed data processed and exported by Apache Flink is stored in Hologres. Then, Hologres writes and queries data in real-time at high concurrency.
Hologres Best Practices
Using Hologres helps simplifying the structure of the 2.0 real-time data warehouse architecture, save resources, and implement unified stream and batch processing. We are still using this architecture. This section describes Hologres best practices in specific search and recommendation scenarios based on this architecture.
Best Practices in Row Store Mode
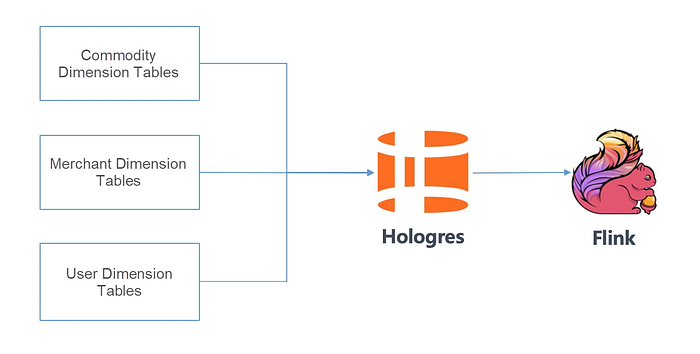
Hologres supports row store and column store modes. The row store mode is friendly to KV queries and is suitable for point queries and scans based on primary keys. The tables that are stored in row store mode are similar to HBase tables. Different tables store dimension information for different entities. Apache Flink jobs efficiently read dimension tables and associate them with entities in real-time streams.
Best Practices in Column Store Mode
By default, tables are stored in Hologres in column store mode. This mode is friendly to OLAP scenarios and is suitable for various complex queries.
Based on the column store mode, we have built a dashboard for real-time data queries in search and recommendation businesses. This dashboard supports real-time data filtering in dozens of dimensions. When the maximum RPS exceeds 5 million, you can still query the aggregation metrics for multiple dimensions within seconds.
In addition, set the time-to-live (TTL) for Hologres tables to avoid resource waste. Generally, TTL is set to 48 hours for a real-time table, and data generated 48 hours ago is automatically deleted. You ca query data generated in the last two days on the dashboard.
Best Practices for Unified Stream and Batch Processing
Hologres supports ad-hoc queries and the analysis of real-time detail data. It also directly accelerates queries of MaxCompute offline tables. Therefore, we use this feature to implement unified stream and batch queries, that is real-time offline federated analytics.
During Tmall promotions, we used the federated analytics capability of Hologres to set up the year-on-year dashboard for the goal completion rate of core merchants, providing effective support for operational algorithms and decision-making.
We simplified the development of the goal completion rate dashboard using real-time offline federated analytics. Specifically, Hologres queries metrics on the promotion day in real-time and divides the real-time table metrics of the day by the target metrics set in the offline table. This allows operators to see the core merchants’ goal completion rates for the day.
The computational logic for the year-on-year dashboard is similar. Run SQL statements to join the real-time table and the offline table from the previous year to compute key metrics.
All computing is completed in Hologres. You only need to use an SQL statement to specify the computational logic, without additional data development. Only one set of code is used and one copy of data is stored, facilitating development and O&M and achieving unified stream and batch processing.

High-concurrency Real-time Update
In some scenarios, you must write incremental data to the OLAP engine in real-time and update the written data.
For example, upon order attribution, an Apache Flink real-time job joins the order submission stream and the progress clickstream and associates the last click event before order submission. When multiple click events arrive in sequence, you must update the order attribution details. In this case, you must update the original data by using the primary key of the data to ensure the accuracy of order attribution data. In practice, Hologres can update up to 500,000 data records, meeting the demand for high-concurrency real-time updates.
Outlook
We hope to continuously improve the existing real-time data warehouses based on the Hologres engine in the following aspects.
Real-time Table Joins
Hologres supports joins between tables that contain tens of billions of records and tables that contain hundreds of millions of records. Such joins are performed in seconds in response to queries. This feature allows you to perform real-time join computing in the Hologres query phase to perform dimension table association that must be completed by an Apache Flink job in the data processing phase. For example, assume table 1 is a details table and table 2 is a user dimension table. In the query phase, the join operation filters the user dimension table and then associates it with the details table to filter data. Such improvements offer several benefits:
1) They reduce the amount of data in Hologres to avoid a large amount of redundant data in the real-time table. For example, data with the same commodity ID may be repeatedly stored.
2) They improve the timeliness of dimension attributes in real-time data and perform a real-time join operation on dimension table data for computing in the query phase. In this way, you always use the latest dimension attributes to filter data.
Persistent Storage
In the future, we will explore how to persistently store real-time computing results in common dimensions by using the computing and storage capabilities of Hologres.
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
